🌟 NeSy: Neuro-Symbolic Diagnostic Framework
![]()
NeSy is a diagnostic assistance framework that bridges the gap between neural natural language processing and symbolic knowledge representation. By integrating Large Language Models (LLMs) with a Knowledge Graph (Neo4j), the system provides a robust pipeline for disease inference based on standardized medical ontologies.
⚠️ Disclaimer: NeSy is a research prototype and is not intended for clinical use. Do not use for actual medical diagnosis.
🎯 Research Contribution
NeSy makes the following contributions to the field of clinical decision support:
1. A Validated Neuro-Symbolic Pipeline for Symptom-Driven Disease Inference
NeSy proposes and evaluates a complete pipeline that integrates LLM-based symptom extraction with Knowledge Graph reasoning over standardized biomedical ontologies (DOID, SYMP). Unlike pure LLM approaches, the symbolic layer guarantees that all inferences are grounded in peer-reviewed ontological relationships, eliminating the risk of hallucinated diagnoses.
2. Empirical Evaluation of 7 LLMs for Medical NLP Extraction
A systematic, metric-driven comparison of models ranging from 3B to 120B parameters — both local and cloud-deployed — was conducted across 100 test cases. Results reveal a counter-intuitive “High-Intelligence Bias”: larger models tend to extract clinically accurate but ontology-misaligned terms, causing them to underperform smaller, instruction-compliant models.
| Model | Size | Type | F1 Score |
|---|---|---|---|
| qwen2.5:14b | 14B | Local | 0.825 ✅ |
| llama3:8b | 8B | Local | 0.800 ✅ |
| mistral-nemo:12b | 12B | Local | 0.790 |
| phi4:14b | 14B | Local | 0.772 |
| llama3.2:3b | 3B | Local | 0.731 |
| llama-4-scout-17b | 17B | Cloud | 0.763 |
| gpt-oss-120b | 120B | Cloud | 0.691 |
✅
qwen2.5:14bachieved the highest F1 score, outperforming models up to 8× larger.
3. IC-Weighted, Square-Root Normalized Scoring for Disease Ranking
A scoring formula is introduced that combines Information Content (IC) weighting with square-root normalization to prevent broad diseases from dominating inference results:
\[normalized\_{score} = \frac{\sum IC(matched\_{symptoms})}{\sqrt{count(disease\_{symptoms})}}\]This ensures specificity over quantity — a disease with two high-IC symptoms can outrank a disease with ten generic symptoms, providing a fairer and more clinically meaningful ranking.
4. Deterministic Absent-Symptom Filtering with 100% Accuracy
The symbolic Cypher-based inference layer supports explicit negation: symptoms the patient does not have actively exclude matching diseases from the ranked results. Validated across 1,263 test cases, the exclusion mechanism achieves:
| Metric | Result |
|---|---|
| Exclusion Accuracy | 100% |
| Survival Accuracy | 100% |
| Collateral Filtering Errors | 0 |
This confirms that the negation filter operates deterministically — every absent symptom reliably blocks similar diseases, while the target disease remains unaffected.
🧬 Biomedical Ontologies
NeSy grounds its symbolic reasoning in standardized, peer-reviewed medical ontologies. This ensures that the system’s knowledge base is medically accurate, hierarchically structured, and free from the hallucinations typical of pure LLM approaches.
🦠 DOID
(Human Disease Ontology): A standardized map of human diseases. It allows the system to understand the relationships between different medical conditions.

🔍 Query for Disease Count:
MATCH (d:Disease)
RETURN count(d);
Total Diseases Counted: 14460
🩺 SYMP
(Symptom Ontology): Provides a standardized vocabulary for clinical signs and symptoms. NeSy uses this to extract, classify, and mathematically weight the symptoms reported by the user.

🔍 Query for Symptom Count:
MATCH (s:Symptom)
RETURN count(s);
Total Symptoms Counted: 1019
Grounding Versions
| Ontology | Local Version | Release Cycle | Status | Source |
|---|---|---|---|---|
| DOID | 2025-09-30 | Monthly | Stable | Download |
| SYMP | 2024-05-17 | Irregular | Up-to-date | Download |
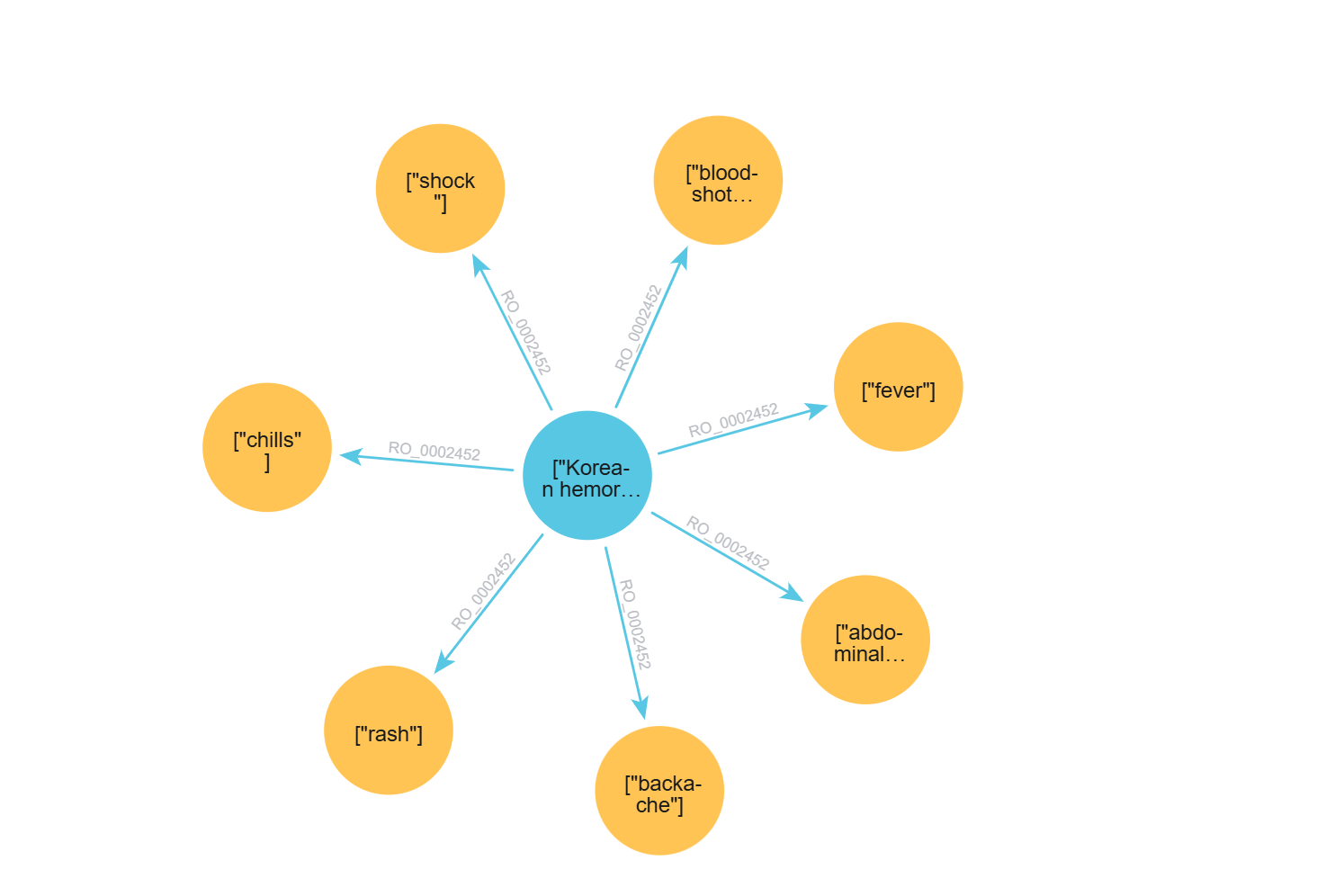
🔗 The Connection (RO_0002452)
In the world of medical data, the link between a disease and its symptoms is formally called RO_0002452 (simply meaning has symptom).
RO_0002452 is the formal identifier for the has_symptom relation defined in the Relations Ontology (RO) — a standard library of biomedical relations maintained by the OBO Foundry community. This relation formally connects the Disease class to the Symptom class and serves as the foundation for interoperability between biomedical ontologies such as DOID (Disease Ontology) and SYMP (Symptom Ontology).
🤔 Why OWL Restriction Instead of a Direct Edge?
➡️ Direct Relationship (Standard Property Graph)
In standard graph databases (e.g., Neo4j), a connection is modeled as a simple binary edge between two nodes:
(:Disease)-[:HAS_SYMPTOM]->(:Symptom)
This is a first-order atomic statement — without quantification, without logical force:
\[has\\_symptom(Disease, Symptom)\]The edge merely states that a connection exists, but says nothing about which instances it applies to or under what conditions.
🦉 OWL Restriction (Ontological Axiom)
Formal biomedical ontologies (DOID, HP, SYMP) are authored in the W3C OWL 2 DL standard, which uses Description Logic (DL). The relation RO_0002452 is not declared as a simple edge in OWL, but rather as an existential restriction (owl:Restriction):
| Symbol | OWL Correspondent | Meaning |
|---|---|---|
| $\sqsubseteq$ | SubClassOf |
every instance of Disease… |
| $\exists$ | owl:someValuesFrom |
…has at least one relation… |
RO_0002452 |
ObjectProperty |
…via has_symptom… |
Symptom |
owl:Class |
…to an instance of the Symptom class |
Logical translation: “Every instance of the Disease class must be connected to at least one instance of the Symptom class via the has_symptom relation.”
🧩 How neosemantics (n4sch) Translates OWL into Neo4j
When the neosemantics library parses an OWL/RDF file, it cannot directly represent anonymous OWL restrictions as simple Neo4j edges — because an OWL restriction is not a binary relation but a complex logical structure. Instead, it creates an intermediate anonymous node that represents the restriction itself:
┌─────────────────────┐
│ (d:Disease) │ ← DOID term (e.g., DOID:9351 - diabetes mellitus)
└──────────┬──────────┘
│
│ [:n4sch__SCO_RESTRICTION]
│ r.onPropertyURI = "http://purl.obolibrary.org/obo/RO_0002452"
▼
┌─────────────────────┐
│ [owl:Restriction] │ ← Anonymous node (blank node)
└──────────┬──────────┘
│
│ [:n4sch__SVF] (someValuesFrom)
▼
┌─────────────────────┐
│ (s:Symptom) │ ← SYMP term (e.g., SYMP:0000570 - polydipsia)
└─────────────────────┘
This three-step structure is a direct consequence of the RDF blank node mechanism that OWL uses for anonymous restrictions, which neosemantics maps into Neo4j nodes and edges.
🔍 Cypher Query for Counting has_symptom Relations
MATCH ()-[r:n4sch__SCO_RESTRICTION]->()
WHERE r.onPropertyURI = "http://purl.obolibrary.org/obo/RO_0002452"
RETURN count(r);
Result: 2259 relations of type has_symptom between DOID and SYMP terms.
🧠 End-to-end Neuro-Symbolic Pipeline
The system is divided into two primary workflows: the Runtime Pipeline and the Preparation Pipeline.
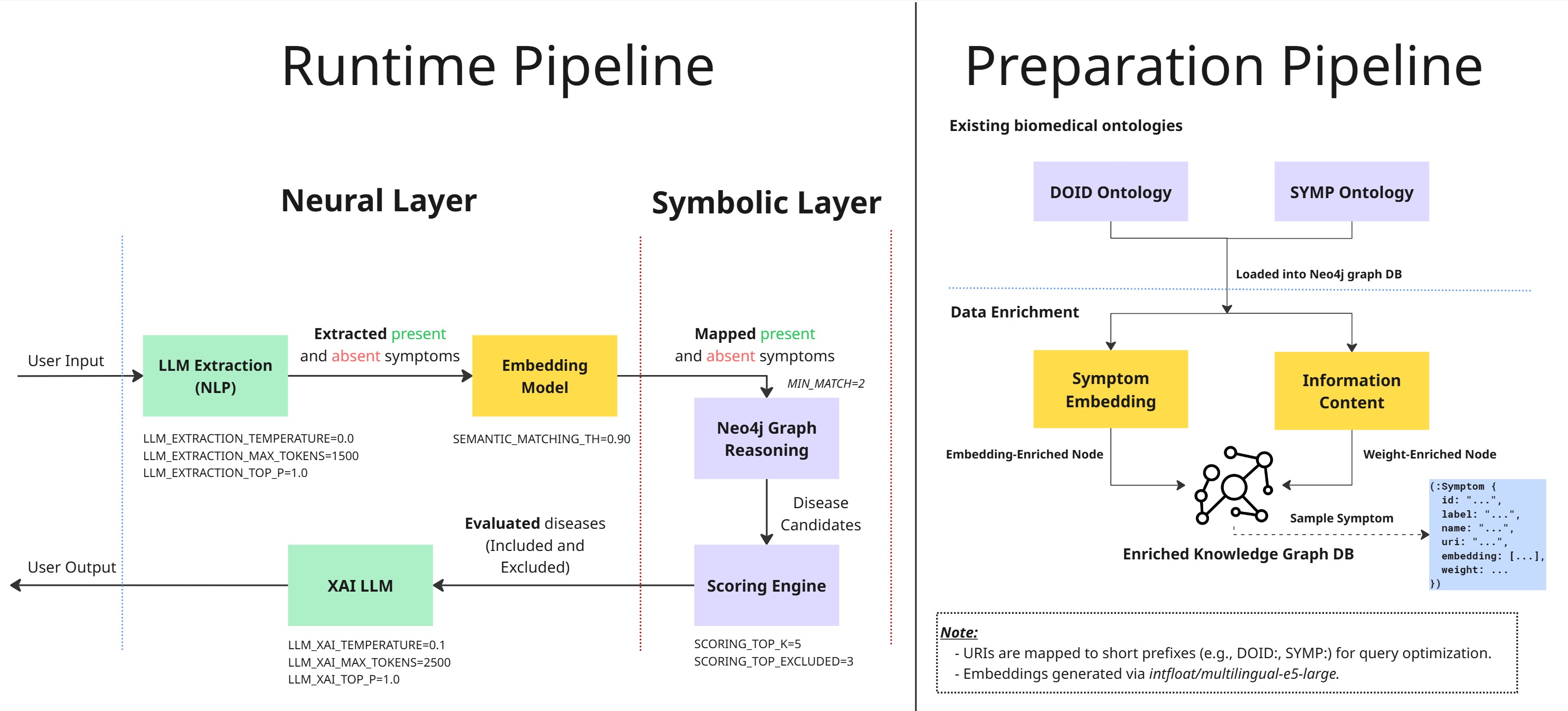
⚙️ Preparation Pipeline
The preparation phase is a two-step process:
Step 1: Ontology loading
Existing biomedical ontologies (DOID and SYMP) are parsed and loaded into the Neo4j Graph Database.
-
This establishes the initial symbolic structure, mapping diseases to symptoms through hierarchical relationships.
-
URIs are mapped to short prefixes (e.g., DOID:, SYMP:) to optimize storage and query performance.
📘 Neo4j & Ontology Setup Guide — Follow this guide to install Neo4j, configure plugins, and load the data.
Step 2 Data Enrichment
Before the system can perform inferences, it undergoes a data enrichment phase:
-
Symptom Embedding: Generates high-dimensional vector representations for symptoms using the
intfloat/multilingual-e5-large model. -
Information Content (IC): Calculates IC metrics to weight the significance of each symptom within the graph hierarchy as follows:
\[IC(s) = \log \left( \frac{N_{total}}{f(s) + 1} \right)\]Where:
- $N_{total}$ is the total number of diseases in the database.
- $f(s)$ is the frequency of symptom $s$ (the number of diseases that feature this symptom).
- The $+1$ term is a smoothing factor to ensure stability.
This counts how many diseases reference a specific symptom via the
RO_0002452(has symptom) relationship and assigns the calculated IC score.The resulting
ICis permanently stored as theweightproperty on eachSymptomnode within the Neo4j graph. This shifts the heavy mathematical computation to the preparation phase. -
Enriched Graph: Stores nodes with attributes like URIs, labels, embeddings, and weights in a Neo4j Graph DB.
📚 Notebook Directory & Workflow — Follow these steps to prepare your Jupyter environment and run the preparation pipeline.
⚡Runtime Pipeline
The active diagnostic process follows a neuro-symbolic approach:
🟢 Neural Layer
-
LLM Extraction (NLP): The system uses an LLM to parse unstructured user input. It identifies mentions of clinical signs and symptoms, filtering out noise and irrelevant context to isolate core medical entities.
-
Embedding Model: Extracted symptoms are passed through the
intfloat/multilingual-e5-large modelmodel. This transforms text into high-dimensional vectors (embeddings). This step is crucial for Semantic Search, allowing the system to understand that “headache” and “cephalalgia” are semantically identical, even if the exact words differ. -
XAI LLM (Explainable AI): Acts as the final synthesis bridge. It takes the structured inference results from the Symbolic Layer and translates them into natural language explanations, ensuring the diagnostic process is transparent and interpretable for the end-user. Instead of just showing a score, it generates a transparent explanation: “Based on the reported symptom of [Symptom A], which is a high-weighted indicator for [Disease B] in the DOID ontology…”
🟣 Symbolic Layer:
-
Neo4j Graph Reasoning: This is the core of the “Symbolic” engine. It performs a Vector Similarity Search between the user’s symptom embeddings and the pre-computed embeddings stored in the graph. Once matches are found, it traverses the symbolic relationships (e.g., RO_0002452 - has_symptom) to find all diseases connected to the identified symptoms within the DOID/SYMP hierarchy.
-
Scoring Engine: Disease ranking is not a simple count of matching symptoms. Instead, it utilizes a sophisticated Normalized Weighted Sum approach:
-
Weighted Sum (
\[total\_{score} = \sum IC(matched\_{symptoms})\]total_score): The Neo4j engine identifies diseases connected to the user’s symptoms and sums the pre-calculated weights (IC) of all matching symptoms. -
Square Root Normalization (
\[normalized\_{score} = \frac{total\_{score}}{\sqrt{count(disease\_{symptoms})}}\]normalized_score): To prevent “broad” diseases (those with a high number of general symptoms) from unfairly dominating the results, we normalize the score by the square root of the total number of symptoms associated with that disease.
-
Key advantages of this approach:
-
Specificity over Quantity: A disease with two highly specific (high IC) symptoms can outrank a disease with ten common (low IC) symptoms.
-
Bias Mitigation: The square root normalization ensures a fair balance between specific diagnostic indicators and the overall complexity of the disease profile.
📂 Project Structure
NeSy/
├── docs/ # Detailed documentation for database and ontology setup
│ └── neo4j_setup.md # Step-by-step guide for Neo4j and n10s
├── data/ # Contains the neo4j.dump file for quick database restore
├── notebooks/ # Jupyter notebooks for IC calculation and vector embeddings
│ └── README.md # Notebooks setup and execution guide
├── backend/ # FastAPI application and Neuro-Symbolic reasoning engine
│ └── README.md # API installation and environment configuration
├── assets/images/ # Architecture diagrams and visualizations
├── _config.yml # GitHub Pages configuration
├── index.md # GitHub Pages landing page
├── LICENSE # MIT License
└── README.md # Main project overview
🔬 Limitations
- Knowledge graph coverage is bounded by DOID and SYMP ontology versions — rare or newly described diseases may be absent
- The system performs inference, not diagnosis — results represent probabilistic candidates, not clinical conclusions
- Multilingual support depends on
intfloat/multilingual-e5-large— performance may vary across languages - IC weights are computed at preparation time; updating ontologies requires re-running the enrichment pipeline
🚀 Getting Started
To get the system up and running, follow these modules in order:
- Database: Restore the graph using the Neo4j Setup Guide.
- Ollama: Local Ollama Setup Ollama Setup Guide.
- Notebooks: Preparation phase and testing Notebooks Guide.
- API: Launch the backend following the Backend README.
- Pyenv: Pyenv setup Pyenv Setup Guide.
🧪 Test Results
- NLP test: NLP Layer Test Results NLP Test Results.
- Embedding test: Embedding Layer Test Results Embedding Test Results.
- Inference and Scoring test: Inference and Scoring Layer Test Results Inference and Scoring Test Results.
- Explainable AI test: XAI Test Results Explainable AI Test Results.
License
Distributed under the MIT License. See LICENSE for details.